 FlinkClient使用Iceberg
FlinkClient使用Iceberg
[toc]
# 使用FlinkSQL连接 - 基于Hive
下载flink-sql-connector-hive
wget https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-hive-3.1.2_2.11/1.12.1/flink-sql-connector-hive-3.1.2_2.11-1.12.1.jar
启动Flink yarn-session.sh
启动成功后再Yarn Web UI中可以看到

启动时需要加载Flink Iceberg Jar包与hadoop-mapreduce-client-core-3.1.2.jar
启动
sql-client.sh embedded -j /usr/local/service/iceberg/iceberg-flink-runtime-1.14-0.13.1.jar -j /opt/iceberg/flink-sql-connector-hive-3.1.2_2.11-1.12.1.jar -j /usr/local/service/flink/lib/hadoop-mapreduce-client-core-3.1.2.jar shell
# 查看CataLog
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
+-----------------+
1 row in set
2
3
4
5
6
7
# 创建基于Hive的Catalog
# 创建catalog
catalog只是声明了,该catalog的文件存储格式是iceberg以及在hive中实际存储的路径。
catalog每次进入客户端都需要建一次catalog.
模板:
CREATE CATALOG hive_catalog WITH ('type'='iceberg','catalog-type'='hive','uri'='hivemetastore_ip:hivemetastore_port','clients'='5','property-version'='1','warehouse'='hdfs:///usr/hive/warehouse/');
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',
'catalog-type'='hive',
'uri'='thrift://10.16.0.3:7004',
'clients'='5',
'property-version'='1',
'warehouse'='/user/hive/warehouse'
);
2
3
4
5
6
7
8
创建成功
Flink SQL> CREATE CATALOG hive_catalog WITH (
> 'type'='iceberg',
> 'catalog-type'='hive',
> 'uri'='thrift://10.16.0.3:7004',
> 'clients'='5',
> 'property-version'='1',
> 'warehouse'='/user/hive/warehouse'
> );
[INFO] Execute statement succeed.
2
3
4
5
6
7
8
9
# 创建数据库
CREATE DATABASE hive_catalog.iceberg_db;
# 创建表
CREATE TABLE hive_catalog.iceberg_db.t1 (id BIGINT COMMENT 'unique id',data STRING);
# 写入数据
INSERT INTO hive_catalog.iceberg_db.t1 values(1, 'tom');
可能报错:
Flink SQL> INSERT INTO hive_catalog.iceberg_db.t1 values(1, 'tom'); [INFO] Submitting SQL update statement to the cluster... [ERROR] Could not execute SQL statement. Reason: java.net.ConnectException: Connection refused1
2
3
4解决方法:
这个问题报错比较笼统。真实的原因是sql-client无法连接到Flink集群的job manager。
如果使用standalone模式,需要执行
./start-cluster.sh启动一个standalone集群。如果使用Yarn session模式,启动
./yarn-session,则需要:
- 启动sql client之前需要export HADOOP_CLASSPATH环境变量。
- 提交yarn session和启动sql client需要使用同一个用户,否则会找不到yarn session对应的application id。
- 确保当前机器的Yarn客户端配置无问题。可通过执行yarn命令是否能正常返回集群信息确认。
# 查询数据
SELECT count(*) from hive_catalog.iceberg_db.t1;
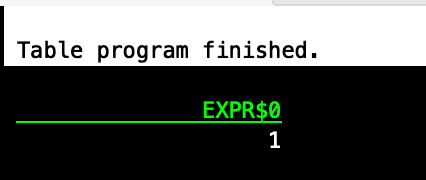
可能报错:
[ERROR] Could not execute SQL statement. Reason: java.lang.ClassNotFoundException: org.apache.hadoop.mapred.JobConf1
2解决方法:
缺少
hadoop-mapreduce-client-core-3.1.0.jar包在服务器上查找这个jar包
find /usr/local/service/ -name "*.jar" | xargs grep -Hsli org.apache.hadoop.mapred.JobConf1启动FlinkSQL时指定该jar包
sql-client.sh embedded -j /usr/local/service/iceberg/iceberg-flink-runtime-1.14-0.13.1.jar -j /opt/iceberg/flink-sql-connector-hive-3.1.2_2.11-1.12.1.jar -j /usr/local/service/flink/lib/hadoop-mapreduce-client-core-3.1.2.jar shell1
# 数据HDFS查看
hive> dfs -ls /user/hive/warehouse/iceberg_db.db/t1/data;
Found 1 items
-rw-r--r-- 3 hadoop supergroup 672 2022-10-10 13:37 /user/hive/warehouse/iceberg_db.db/t1/data/00000-0-a0bb4bf5-2bd1-4d8e-9b32-e6bf886f8d8c-00001.parquet
2
3
# Flink SQL 客户端总结
- 多个Flink SQL客户端 Catalog 不共享,每次启动Flink SQL客户端需要重新创建catalog
- database、table、数据是共享的,数据会落盘
# 使用FlinkSQL连接 - 基于Hadoop
刚刚基于Hive的Iceberg写入已经写入成功,这里介绍基于Hadoop写入
# 启动Flink SQL Client
sql-client.sh embedded -j /usr/local/service/iceberg/iceberg-flink-runtime-1.14-0.13.1.jar -j /usr/local/service/flink/lib/hadoop-mapreduce-client-core-3.1.2.jar shell
# 创建Catalog
在 Flink SQL Client 中执行
CREATE CATALOG hadoop_catalog WITH (
'type'='iceberg',
'catalog-type'='hadoop',
'warehouse'='hdfs:///user/hive/warehouse/iceberg_hadoop_catalog',
'property-version'='1'
);
2
3
4
5
6
Flink SQL> CREATE CATALOG hadoop_catalog WITH (
> 'type'='iceberg',
> 'catalog-type'='hadoop',
> 'warehouse'='hdfs:///user/hive/warehouse/iceberg_hadoop_catalog',
> 'property-version'='1'
> );
[INFO] Execute statement succeed.
Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| default_catalog |
| hadoop_catalog |
+-----------------+
2 rows in set
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 创建数据库
create database hadoop_catalog.iceberg_db;
# 创建表
CREATE TABLE `hadoop_catalog`.`iceberg_db`.`sample` (
id BIGINT COMMENT 'unique id',
data STRING
);
2
3
4
在HDFS中可以看到创建的表目录
hdfs dfs -ls /user/hive/warehouse/iceberg_hadoop_catalog/iceberg_db/sample;
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2022-10-10 14:28 /user/hive/warehouse/iceberg_hadoop_catalog/iceberg_db/sample/metadata
2
3
# 写入数据
INSERT INTO `hadoop_catalog`.`iceberg_db`.`sample` VALUES (1, 'a');
在HDFS中查看
hdfs dfs -ls /user/hive/warehouse/iceberg_hadoop_catalog/iceberg_db/sample/data;
Found 1 items
-rw-r--r-- 3 hadoop supergroup 658 2022-10-10 14:29 /user/hive/warehouse/iceberg_hadoop_catalog/iceberg_db/sample/data/00000-0-64851a1a-f776-470d-980d-a3bc4eeabe1c-00001.parquet
2
3
# 查看数据
select * from `hadoop_catalog`.`iceberg_db`.`sample`;
# 执行数据更新操作-INSERT根据主键数据替换
正常执行时更新报错
Flink SQL> update `hadoop_catalog`.`iceberg_db`.`sample` set data='lalala' where id = '1';
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.TableException: Unsupported query: update `hadoop_catalog`.`iceberg_db`.`sample` set data='lalala' where id = '1'
2
3
原因:
创建表时未指定‘format-version’=‘2’
重要配置
- 设置metadata保留次数
- ‘format-version’=‘2’,配置了才支持delete和update
表格式有两种
表格式有版本1和版本2,可以通过
format-version参数进行指定,默认值是1版本1: 分析型数据表
使用的是不可变的文件格式:parquet、avro、orc
版本2:行级更新和删除
当进行更新和删除,会添加不可变的delete files,来表明行被更新或删除。同时该版本对writer有更严格的要求
修改后建表语句
CREATE TABLE `hadoop_catalog`.`iceberg_db`.`sample8` (
id BIGINT COMMENT 'unique id',
data STRING,
age INT,
PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2', 'write.upsert.enabled'='true');
2
3
4
5
6
写入数据
INSERT INTO `hadoop_catalog`.`iceberg_db`.`sample8` VALUES (1, 'a',10);
INSERT INTO `hadoop_catalog`.`iceberg_db`.`sample8` VALUES (2, 'b',12);
2
再次写入数据
INSERT INTO `hadoop_catalog`.`iceberg_db`.`sample8`(id,data) VALUES (1, 'b');
查询数据,得到修改后的a
select * from `hadoop_catalog`.`iceberg_db`.`sample8`;
结论:
- INSERT INTO 主键重复插入数据,会将最新插入版本数据完全替换上次的数据
# Flink SQL操作
# Like建表
create table 表名A like 表名B
创建新表,复制表结构
# INSERT OVERWRITE
INSERT OVERWRITE hadoop_catalog.iceberg_db.sample VALUES (1, 'a');
默认会提示失败:
Flink SQL> INSERT OVERWRITE `hadoop_catalog`.`iceberg_db`.`sample` VALUES (1, 'a');
[INFO] Submitting SQL update statement to the cluster...
[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalStateException: Unbounded data stream doesn't support overwrite operation.
2
3
4
原因:Flink SQL Client Iceberg 默认使用流处理模式这里要改为批处理后才能写入
SET execution.type = batch ;
修改回
SET execution.type = streaming ;