 PaddleNLP-情感分析定制化训练
PaddleNLP-情感分析定制化训练
[toc]
# 官网介绍文档
# 结合业务分析经验,定制情感分析
本项目支持从以下方面协助用户,结合业务经验,进一步定制情感分析能力,提高模型对业务数据的理解和分析能力。
- 数据层面:打通 label-studio 平台,定制了情感信息的标注规则,支持根据标注数据自动转换为模型输入样本。
- 属性聚合:结合业务经验,支持传入同义的属性集合,可以增强模型对于数据聚合的能力。
- 隐性观点抽取:结合业务经验,支持自定义隐性观点词表,可以增强模型对于隐性观点的抽取能力。
下面以汽车场景为例,讲解定制汽车垂域的情感分析能力。具体地,将从数据标注及样本构建 - 模型训练 - 模型测试 - 模型预测及效果展示等全流程展开介绍。
# 打通数据标注到训练样本构建
使用
label-studio平台标注数据,具体安装方法参考:训练数据标注支持用户在基于 label_studio 标注业务侧数据后,通过label-studio 导出标注好的json数据, 然后利用本项目提供的
label_studio.py脚本,可以将导出数据一键转换为模型训练数据。在利用
label_studio.py脚本进行数据转换时,需要考虑任务类型的不同,选择相应的样本构建方式,整体可以分为分类和抽取任务。
# 下面根据分类和抽取分别介绍
# 抽取任务(属性级情感分析任务)
属性级的情感分析需要配置的标注任务类型为Relation Extraction,包括属性抽取、观点抽取、属性-观点抽取、属性-情感极性抽取、属性-情感极性-观点词三元组抽取等任务。
# 属性-情感极性-观点词抽取(本介绍章节主要介绍该方法,其他方法也基本一样)
属性-情感极性-观点词(A-S-O)三元组抽取标注内容涉及两类标签:Span 类型标签和 Relation 类型标签。其中Span标签用于定位文本批评中属性、观点词和情感极性三类信息,Relation类型标签用于设置评价维度和观点词、情感倾向之间的关系。
LabelStudio创建方法参考:训练数据标注
标注完成的结果如下图:
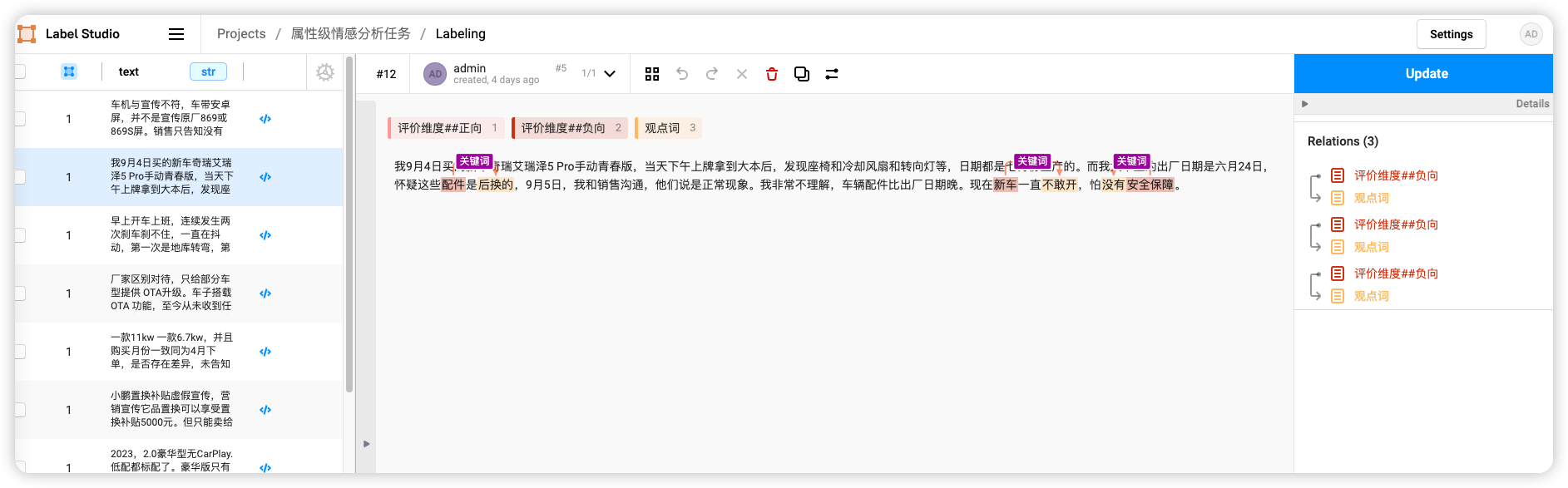
训练样本越多越好,这里我测试只标注了27条。
在label-studio中导出.json文件
# 加强隐性观点抽取能力(可选)
另外,本项目同时支持加强对隐性观点功能抽取的能力,这里需要说明一点,本项目中定义隐性观点是指没有对应属性的纯观点词,如以下示例中的"比较便宜"便是隐性观点。
这是家里人推荐的,说这个车保值,省油,但最后我还是没选,因为我感觉更多的还是要支持国货,选择我们自主品牌的汽车,更重要的是这台车太贵了3所以最后还是选择了瑞虎九
# 加强属性聚合能力(可选)
在用户对产品或服务进行评论时,对某一些属性可能会有不同的说法,这会在后续对属性分析时可能会带来困扰。
如以下示例中的"消费者","顾客"和"客户"。
消费者 顾客 客户
订金 定金
...
2
3
针对这种情况,针对属性相关任务,本项目同时支持用户结合业务经验,通过设置同义的属性词表,加强模型的属性聚合能力。具体来讲,本项目期望通过以下两点,支持对属性聚合能力的建设。
- 支持针对用户给定的属性进行情感分析
- 支持用户提供同义的属性词表,用以加强模型对用户领域属性同义词的理解能力
验证
以下给出了汽车VOC场景的示例,每行代表1类同义词,不同词之间以"空格"隔开。
# vim synonyms.txt
消费者 顾客 客户 人们
订金 定金
2
3
在训练之前我们先测试一下现在的效果
>>> senta("一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知人们。")
[{}]
>>> senta("是否存在差异,未告知人们。")
[{}]
2
3
4
可以通过以下命令,使用synonym_file指定凝聚业务经验的同义属性集合,利用同义属性生成对应的数据样本:
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--synonym_file ./data/synonyms.txt \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--options "正向" "负向" "未提及" \
--negative_ratio 5 \
--is_shuffle True \
--seed 1000
2
3
4
5
6
7
8
9
10
训练后效果
>>> senta("是否存在差异,未告知人们。")
[{'评价维度': [{'text': '人们', 'start': 10, 'end': 12, 'probability': 0.5985828109579643, 'relations': {'观点词': [{'text': '未告知', 'start': 7, 'end': 10, 'probability': 0.9788291049591962}], '情感倾向[正向,负向,未提及]': [{'text': '负向', 'probability': 0.9931167025701022}]}}]}]
>>> senta("一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知人们。")
[{}]
2
3
4
阶段总结:我们发现不是完全可以识别我们配置的近义词。
怀疑原因:涉及到消费者 顾客 客户 人们这几个词的训练的数据太少
接着下一步,我又训练了几条包含消费者关键词的数据(这里我就加了两条数据~)
数据1: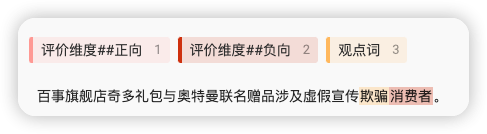
数据2: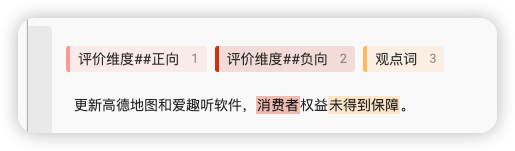
我们只标注了
消费者为评价维度,并没有标注人们这个词,这样才能验证配置的近义词是否生效
重新导出数据->上传->生成样本数据->训练数据
验证结果
>>> senta("一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知人们。")
[{'评价维度': [{'text': '人们', 'start': 40, 'end': 42, 'probability': 0.5459132127560835, 'relations': {'观点词': [{'text': '未告知', 'start': 37, 'end': 40, 'probability': 0.9999766350856589}], '情感倾向[正向,负向,未提及]': [{'text': '负向', 'probability': 0.999623989377092}]}}]}]
>>> senta("是否存在差异,未告知人们。")
[{'评价维度': [{'text': '人们', 'start': 10, 'end': 12, 'probability': 0.9990394201152313, 'relations': {'观点词': [{'text': '未告知', 'start': 7, 'end': 10, 'probability': 0.999977469545513}], '情感倾向[正向,负向,未提及]': [{'text': '负向', 'probability': 0.9993659648713731}]}}]}]
2
3
4
证明:样本数据多,配置的近义词是生效的
# 模型训练
python -u -m paddle.distributed.launch --gpus "0" finetune.py \
--train_path ./data/train.json \
--dev_path ./data/dev.json \
--save_dir ./checkpoint \
--learning_rate 1e-5 \
--batch_size 12 \
--max_seq_len 512 \
--num_epochs 30 \
--model uie-senta-base \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device gpu
2
3
4
5
6
7
8
9
10
11
12
13
这里训练轮数我设置了30次,训练次数少了,调用结果会不准(当然实际情况还是要根据真实数据训练结果来评定)
可配置参数说明:
train_path:必须,训练集文件路径。dev_path:必须,验证集文件路径。save_dir:模型 checkpoints 的保存目录,默认为"./checkpoint"。learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为1e-5。batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 16。max_seq_len:模型支持处理的最大序列长度,默认为512。num_epochs:模型训练的轮次,可以视任务情况进行调整,默认为10。model:训练使用的预训练模型。可选择的有uie-senta-base,uie-senta-medium,uie-senta-mini,uie-senta-micro,uie-senta-nano,默认为uie-senta-base。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。valid_steps: 训练过程中模型评估的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。device: 训练设备,可选择 'cpu'、'gpu' 其中的一种;默认为 GPU 训练。
# 模型测试
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.json \
--batch_size 16 \
--max_seq_len 512
2
3
4
5
可配置参数说明:
model_path:必须,进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path:必须,进行评估的测试集文件。batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 16。max_seq_len:文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
运行结果
python evaluate.py --model_path ./checkpoint2/model_best --test_path ./data/test.json --batch_size 16 --max_seq_len 512
[2023-09-11 15:58:47,812] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load './checkpoint2/model_best'.
[2023-09-11 15:58:47,841] [ INFO] - Loading configuration file ./checkpoint2/model_best/config.json
[2023-09-11 15:58:47,841] [ INFO] - Loading weights file ./checkpoint2/model_best/model_state.pdparams
[2023-09-11 15:58:48,913] [ INFO] - Loaded weights file from disk, setting weights to model.
W0911 15:58:48.918774 8771 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0911 15:58:48.923005 8771 gpu_resources.cc:149] device: 0, cuDNN Version: 8.2.
[2023-09-11 15:58:52,496] [ INFO] - All model checkpoint weights were used when initializing UIE.
[2023-09-11 15:58:52,496] [ INFO] - All the weights of UIE were initialized from the model checkpoint at ./checkpoint2/model_best.
If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training.
0%| | 0/33 [00:00<?, ?it/s]/home/aistudio/paddlenlp2.6.0/paddlenlp/transformers/tokenizer_utils_base.py:2481: FutureWarning: The `max_seq_len` argument is deprecated and will be removed in a future version, please use `max_length` instead.
FutureWarning,
/home/aistudio/paddlenlp2.6.0/paddlenlp/transformers/tokenizer_utils_base.py:1884: FutureWarning: The `pad_to_max_length` argument is deprecated and will be removed in a future version, use `padding=True` or `padding='longest'` to pad to the longest sequence in the batch, or use `padding='max_length'` to pad to a max length. In this case, you can give a specific length with `max_length` (e.g. `max_length=45`) or leave max_length to None to pad to the maximal input size of the model (e.g. 512 for Bert).
FutureWarning,
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33/33 [00:07<00:00, 4.16it/s]
[2023-09-11 15:59:00,451] [ INFO] - -----------------------------
[2023-09-11 15:59:00,452] [ INFO] - Class Name: all_classes
[2023-09-11 15:59:00,452] [ INFO] - Evaluation Precision: 0.81878 | Recall: 0.82418 | F1: 0.82147
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
在构造样本过程中,如果设置了最大负例比例negative_ratio,会在样本中添加一定数量的负样本,模型测试默认会对正样本和负样本共同进行评估。特别地,当开启debug模式后,会对每个正例类别分别进行评估,该模式仅用于模型调试:
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.json \
--batch_size 16 \
--max_seq_len 512 \
--debug
2
3
4
5
6
运行结果
[2023-09-11 15:59:34,294] [ INFO] - -----------------------------
[2023-09-11 15:59:34,294] [ INFO] - Class Name: 评价维度
[2023-09-11 15:59:34,294] [ INFO] - Evaluation Precision: 0.80000 | Recall: 0.78873 | F1: 0.79433
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 4.89it/s]
[2023-09-11 15:59:34,706] [ INFO] - -----------------------------
[2023-09-11 15:59:34,706] [ INFO] - Class Name: 观点词
[2023-09-11 15:59:34,706] [ INFO] - Evaluation Precision: 0.67500 | Recall: 0.69231 | F1: 0.68354
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 5.76it/s]
[2023-09-11 15:59:35,404] [ INFO] - -----------------------------
[2023-09-11 15:59:35,404] [ INFO] - Class Name: X的观点词
[2023-09-11 15:59:35,404] [ INFO] - Evaluation Precision: 0.75926 | Recall: 0.73214 | F1: 0.74545
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 5.76it/s]
[2023-09-11 15:59:36,275] [ INFO] - -----------------------------
[2023-09-11 15:59:36,276] [ INFO] - Class Name: X的情感倾向[未提及,正向,负向]
[2023-09-11 15:59:36,276] [ INFO] - Evaluation Precision: 0.91045 | Recall: 0.92424 | F1: 0.91729
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 模型预测效果
这里我们随便找3条数据进行验证
- 在训练样本(train.json)中:
一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知消费者。 - 在测试样本(train.json)中:
小鹏置换补贴虚假宣传,营销宣传它品置换可以享受置换补贴5000元。但只能卖给小鹏官方二手车才能享受5000置换补贴,且二手车评估严重压价,加上置换补贴跟外面评估价一致 。消费者并没有享受置换补贴,存在虚假宣传。且不给退订金。 - 在训练样本(train.json)中:
选择这台车是经过深思熟虑之后才做的决定,因为这是一台性价比非常高的车。比较时尚的外观,充沛的动力,空间也比较大,有好做的也不错,可能销量不太高,但是就像我买 瑞虎八一样,并不是看中它的销量才去选择它,更多的还是因为它的综合属性比较好。 - 不在样本中:``
在默认模型中调用结果
from paddlenlp import Taskflow
schema = [{'评价维度': ['观点词', '情感倾向[正向,负向,未提及]']}]
senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
senta("文本内容")
2
3
4
| 文本 | 结果 |
|---|---|
| 一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知消费者。 | [{}] |
| 小鹏置换补贴虚假宣传,营销宣传它品置换可以享受置换补贴5000元。但只能卖给小鹏官方二手车才能享受5000置换补贴,且二手车评估严重压价,加上置换补贴跟外面评估价一致 。消费者并没有享受置换补贴,存在虚假宣传。且不给退订金。 | [{}] |
| 选择这台车是经过深思熟虑之后才做的决定,因为这是一台性价比非常高的车。比较时尚的外观,充沛的动力,空间也比较大,有好做的也不错,可能销量不太高,但是就像我买瑞虎八一样,并不是看中它的销量才去选择它,更多的还是因为它的综合属性比较好。 | [{"评价维度": [{"text": "销量", "start": 66, "end": 68, "probability": 0.9077473619998528, "relations": {"观点词": [{"text": "不太高", "start": 68, "end": 71, "probability": 0.9795721316931818}], "情感倾向[正向,负向,未提及]": [{"text": "负向", "probability": 0.837533914611555}]}}, {"text": "动力", "start": 46, "end": 48, "probability": 0.9748795537401378, "relations": {"观点词": [{"text": "充沛", "start": 43, "end": 45, "probability": 0.9975238884777546}], "情感倾向[正向,负向,未提及]": [{"text": "正向", "probability": 0.9995073685561557}]}}, {"text": "属性", "start": 110, "end": 112, "probability": 0.6369904440479175, "relations": {"观点词": [{"text": "好", "start": 114, "end": 115, "probability": 0.9976424905745098}], "情感倾向[正向,负向,未提及]": [{"text": "负向", "probability": 0.7637467274340253}]}}, {"text": "外观", "start": 40, "end": 42, "probability": 0.9542350328709404, "relations": {"观点词": [{"text": "时尚", "start": 37, "end": 39, "probability": 0.999613857580357}], "情感倾向[正向,负向,未提及]": [{"text": "正向", "probability": 0.9998425290415867}]}}, {"text": "性价比", "start": 26, "end": 29, "probability": 0.999376452377021, "relations": {"观点词": [{"text": "高", "start": 31, "end": 32, "probability": 0.9995543830081601}], "情感倾向[正向,负向,未提及]": [{"text": "正向", "probability": 0.9989066724983893}]}}, {"text": "空间", "start": 49, "end": 51, "probability": 0.9930068380599977, "relations": {"观点词": [{"text": "大", "start": 54, "end": 55, "probability": 0.9998664895007181}], "情感倾向[正向,负向,未提及]": [{"text": "正向", "probability": 0.9999274025993827}]}}]}] |
在训练后模型测试效果
from paddlenlp import Taskflow
schema = [{'评价维度': ['观点词', '情感倾向[正向,负向,未提及]']}]
senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema, task_path="./checkpoint/model_best")
senta("文本内容")
2
3
4
文本:==一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知消费者。==
结果:
[
{
"评价维度": [
{
"end": 43,
"probability": 0.9999207273803279,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9849026466332234,
"text": "负向"
}
],
"观点词": [
{
"end": 40,
"probability": 0.9999148863779084,
"start": 37,
"text": "未告知"
}
]
},
"start": 40,
"text": "消费者"
}
]
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
发现训练集中的数据,在训练后模型调用结果与我们模型标注一样

文本:==小鹏置换补贴虚假宣传,营销宣传它品置换可以享受置换补贴5000元。但只能卖给小鹏官方二手车才能享受5000置换补贴,且二手车评估严重压价,加上置换补贴跟外面评估价一致 。消费者并没有享受置换补贴,存在虚假宣传。且不给退订金。==
结果:
[
{
"评价维度": [
{
"end": 64,
"probability": 0.6006340852546259,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9998928314971351,
"text": "负向"
}
],
"观点词": [
{
"end": 66,
"probability": 0.7102552867922007,
"start": 64,
"text": "严重"
}
]
},
"start": 62,
"text": "评估"
}
]
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
发现测试集中的数据结果与我们标注的不一致(模型数据太少,训练出的模型调用不准确)

文本:==选择这台车是经过深思熟虑之后才做的决定,因为这是一台性价比非常高的车。比较时尚的外观,充沛的动力,空间也比较大,有好做的也不错,可能销量不太高,但是就像我买瑞虎八一样,并不是看中它的销量才去选择它,更多的还是因为它的综合属性比较好。==
结果:
[
{
"评价维度": [
{
"end": 68,
"probability": 0.9996403173658877,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9989013091909271,
"text": "负向"
}
],
"观点词": [
{
"end": 71,
"probability": 0.9999293098057649,
"start": 68,
"text": "不太高"
}
]
},
"start": 66,
"text": "销量"
},
{
"end": 48,
"probability": 0.9998829398881526,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9999488597547952,
"text": "正向"
}
],
"观点词": [
{
"end": 45,
"probability": 0.9999592308344063,
"start": 43,
"text": "充沛"
}
]
},
"start": 46,
"text": "动力"
},
{
"end": 42,
"probability": 0.9996114000432499,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9999581577044694,
"text": "正向"
}
],
"观点词": [
{
"end": 39,
"probability": 0.9999601843571355,
"start": 37,
"text": "时尚"
}
]
},
"start": 40,
"text": "外观"
},
{
"end": 29,
"probability": 0.9999095220223637,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.999965310242402,
"text": "正向"
}
],
"观点词": [
{
"end": 32,
"probability": 0.9995261083753704,
"start": 31,
"text": "高"
}
]
},
"start": 26,
"text": "性价比"
},
{
"end": 51,
"probability": 0.998529000106231,
"relations": {
"情感倾向[正向,负向,未提及]": [
{
"probability": 0.9999730587887825,
"text": "正向"
}
],
"观点词": [
{
"end": 55,
"probability": 0.9996975101894705,
"start": 53,
"text": "较大"
}
]
},
"start": 49,
"text": "空间"
}
]
}
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
发现训练集中的数据,在训练后模型调用结果与我们模型标注一样

不在训练样本、不在测试样本的数据进行预测
文本==迪Q3这台车动力还是比其他车充沛,大家可以购买!但是就是价格有点贵。==

# 总结
不在训练集中的数据准确度不高,在训练集中的数据能够准确识别,是因为训练数据太少,这里只是做演示。证明了训练出的模型是有效果,如果想提升效果,还需要提升标注的数据,以及标注的准确度。
# 分类任务
# 样本构建:语句级情感分类任务
对于语句级情感分类任务,默认支持2分类:正向 和 负向,可以通过如下命令构造相关训练数据。
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--task_type cls \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--options "正向" "负向" \
--is_shuffle True \
--seed 1000
2
3
4
5
6
7
8
参数介绍:
label_studio_file: 从label studio导出的语句级情感分类的数据标注文件。task_type: 选择任务类型,可选有抽取和分类两种类型的任务,其中前者需要设置为ext,后者需要设置为cls。由于此处为语句级情感分类任务,因此需要设置为cls。save_dir: 训练数据的保存目录,默认存储在data目录下。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。options: 情感极性分类任务的选项设置。对于语句级情感分类任务,默认支持2分类:正向和负向;对于属性级情感分析任务,默认支持3分类:正向,负向和未提及,其中未提及表示要分析的属性在原文本评论中未提及,因此无法分析情感极性。如果业务需要其他情感极性选项,可以通过options字段进行设置,需要注意的是,如果定制了options,参数label_studio_file指定的文件需要包含针对新设置的选项的标注数据。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.
备注:参数options可以不进行手动指定,如果这么做,则采用默认的设置。针对语句级情感分类任务,其默认将被设置为:"正向" "负向";对于属性级情感分析任务,默认将被设置为:"正向" "负向" "未提及"。
# 训练数据-正向、负向、中性
在LabelStudio创建项目
选择文本分类
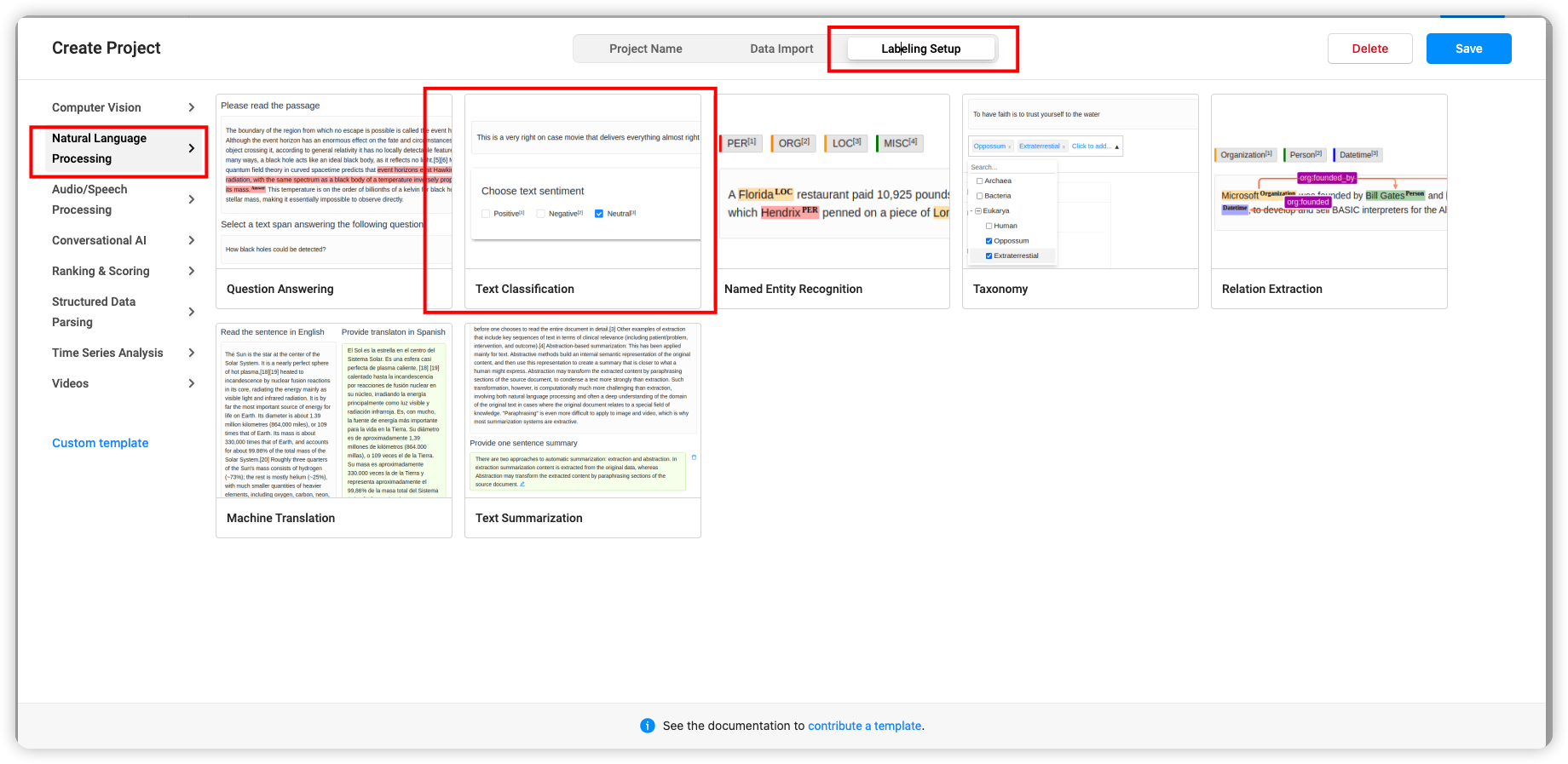
删除默认分类
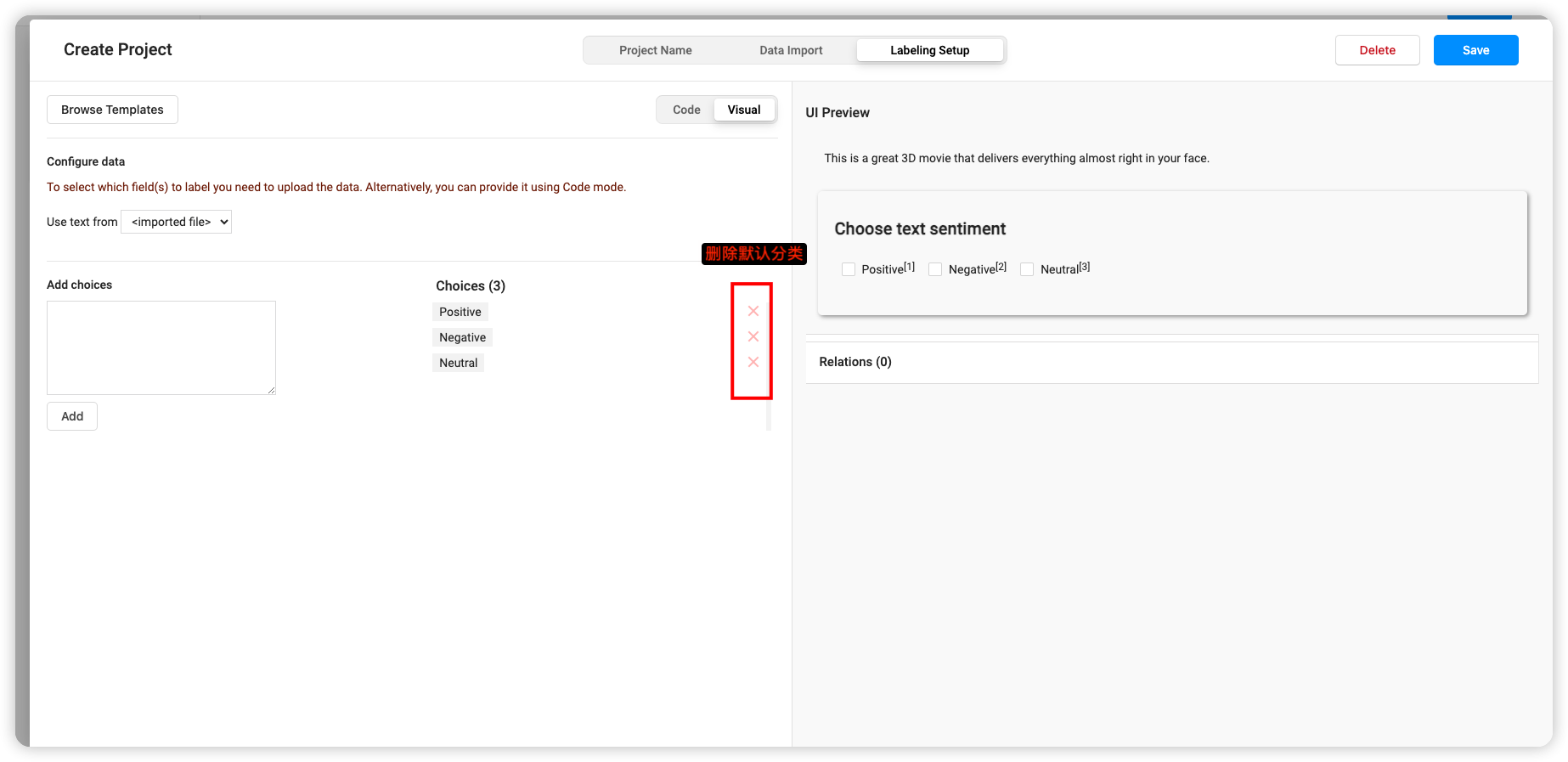
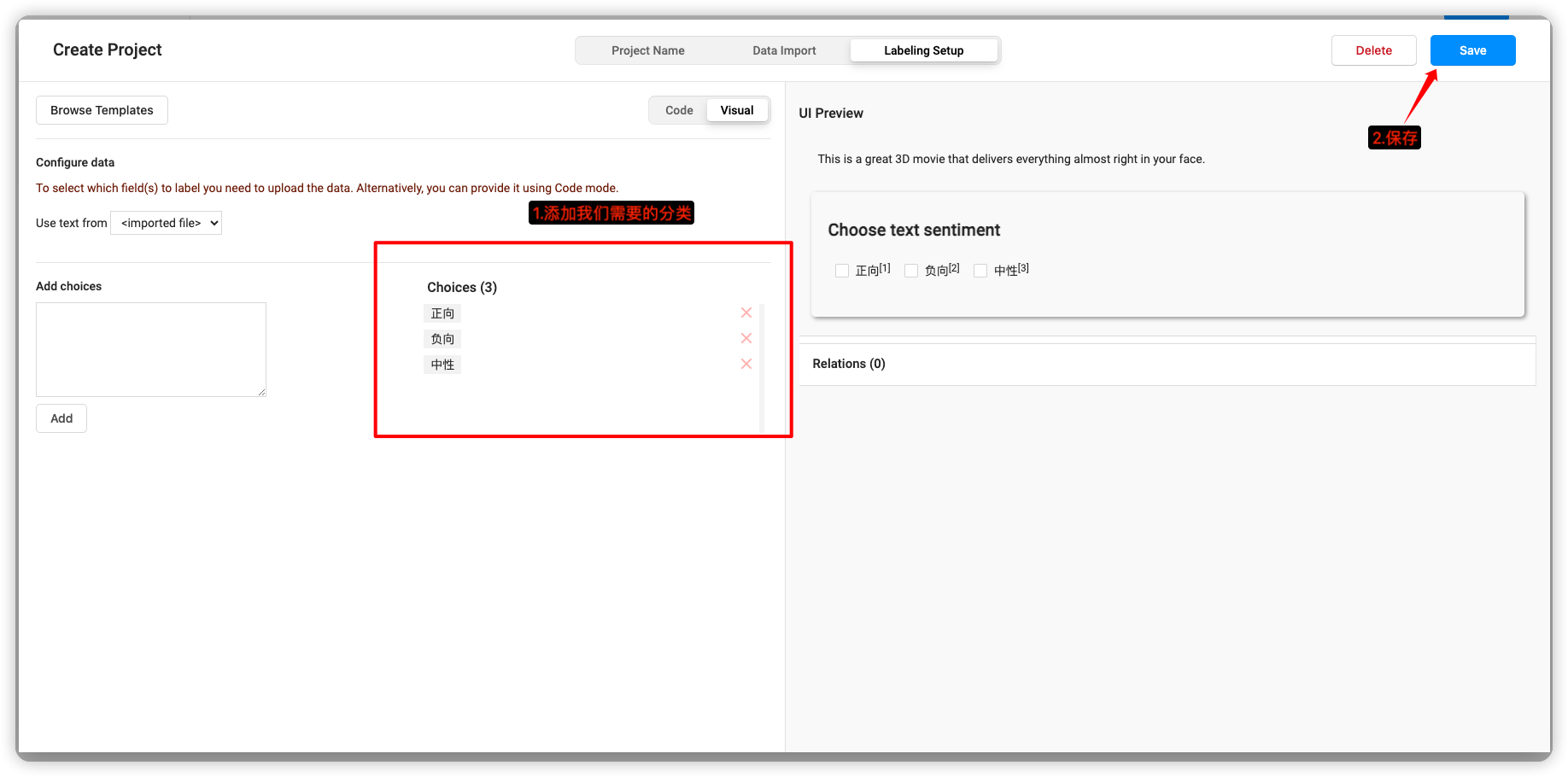
导入数据
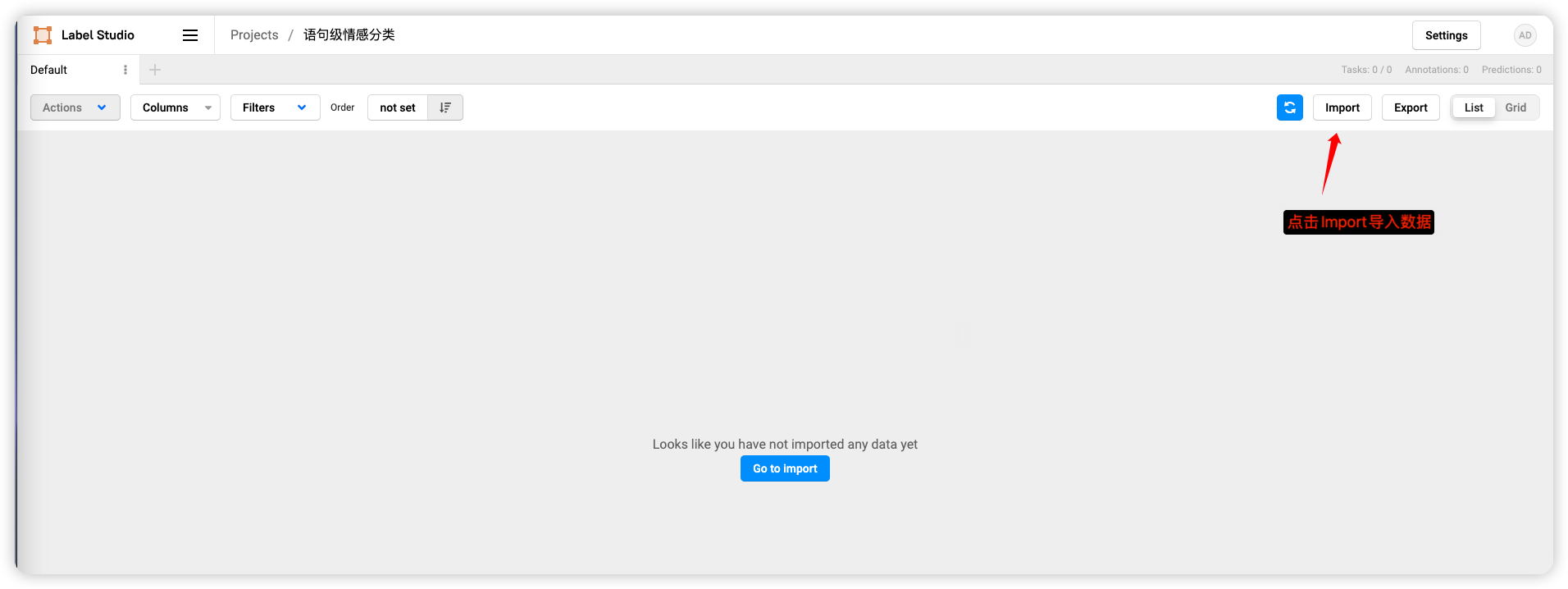

导入成功,在页面可以看到数据
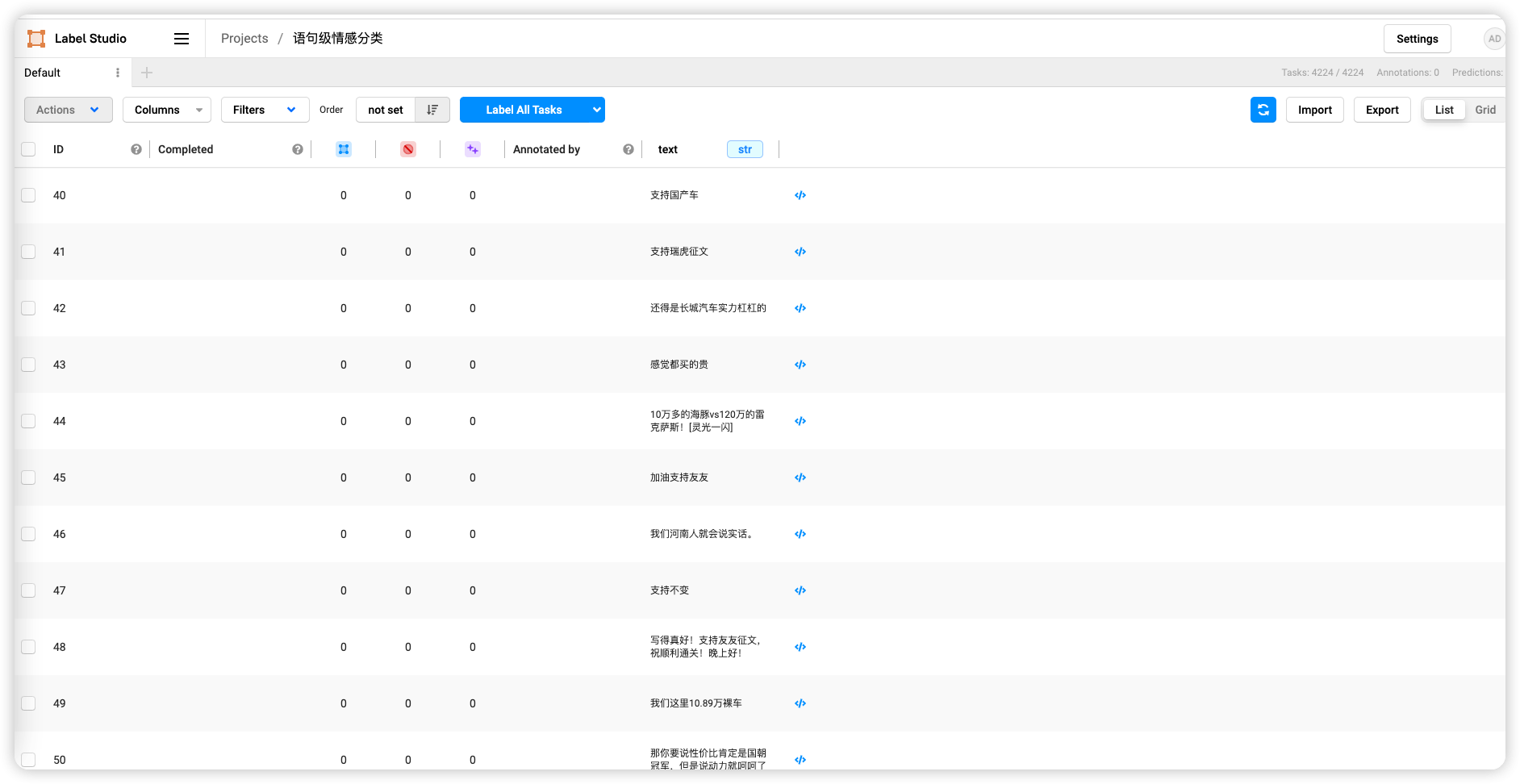
标注数据(这里标注越多越准确)
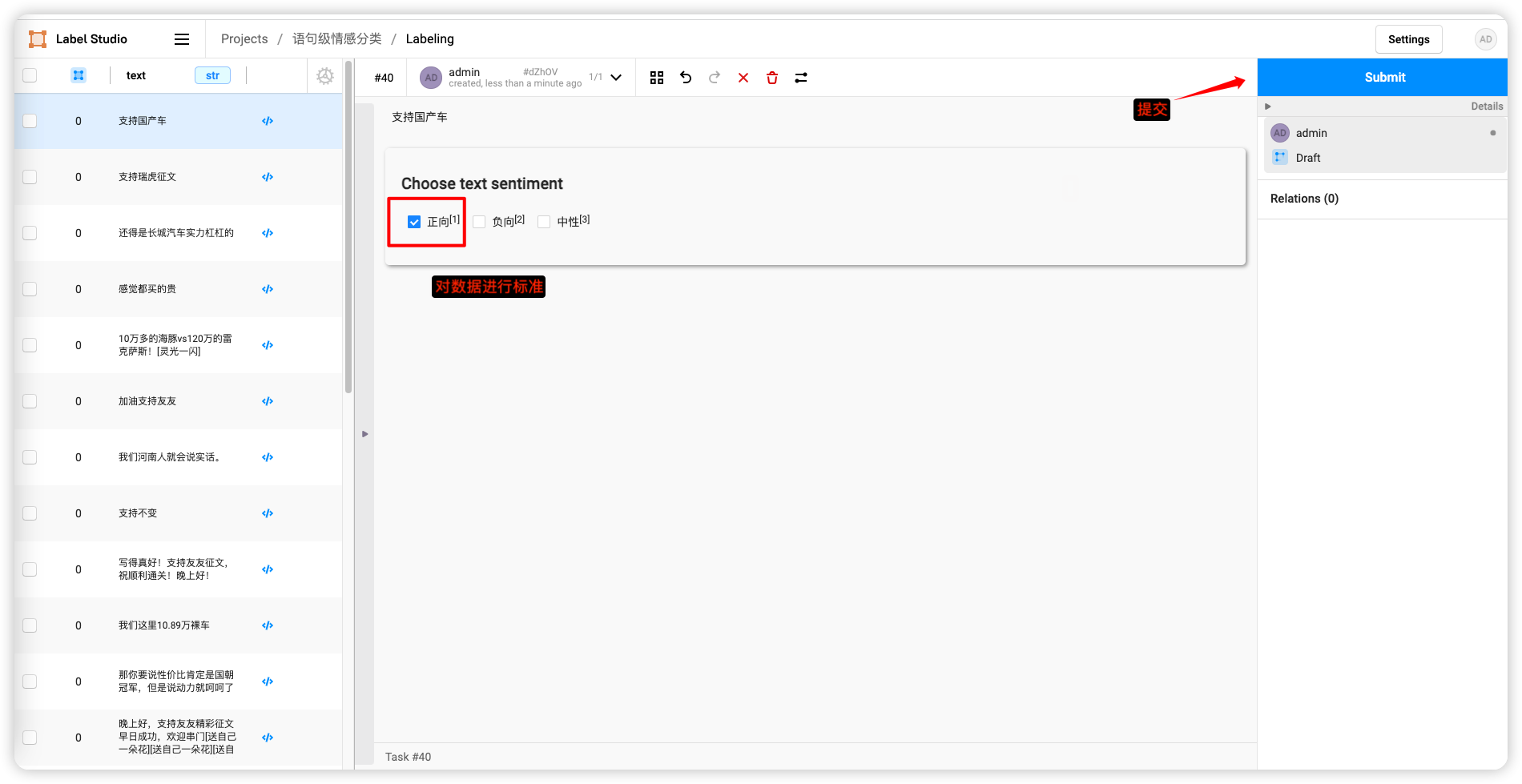
标注完数据,点击Export导出
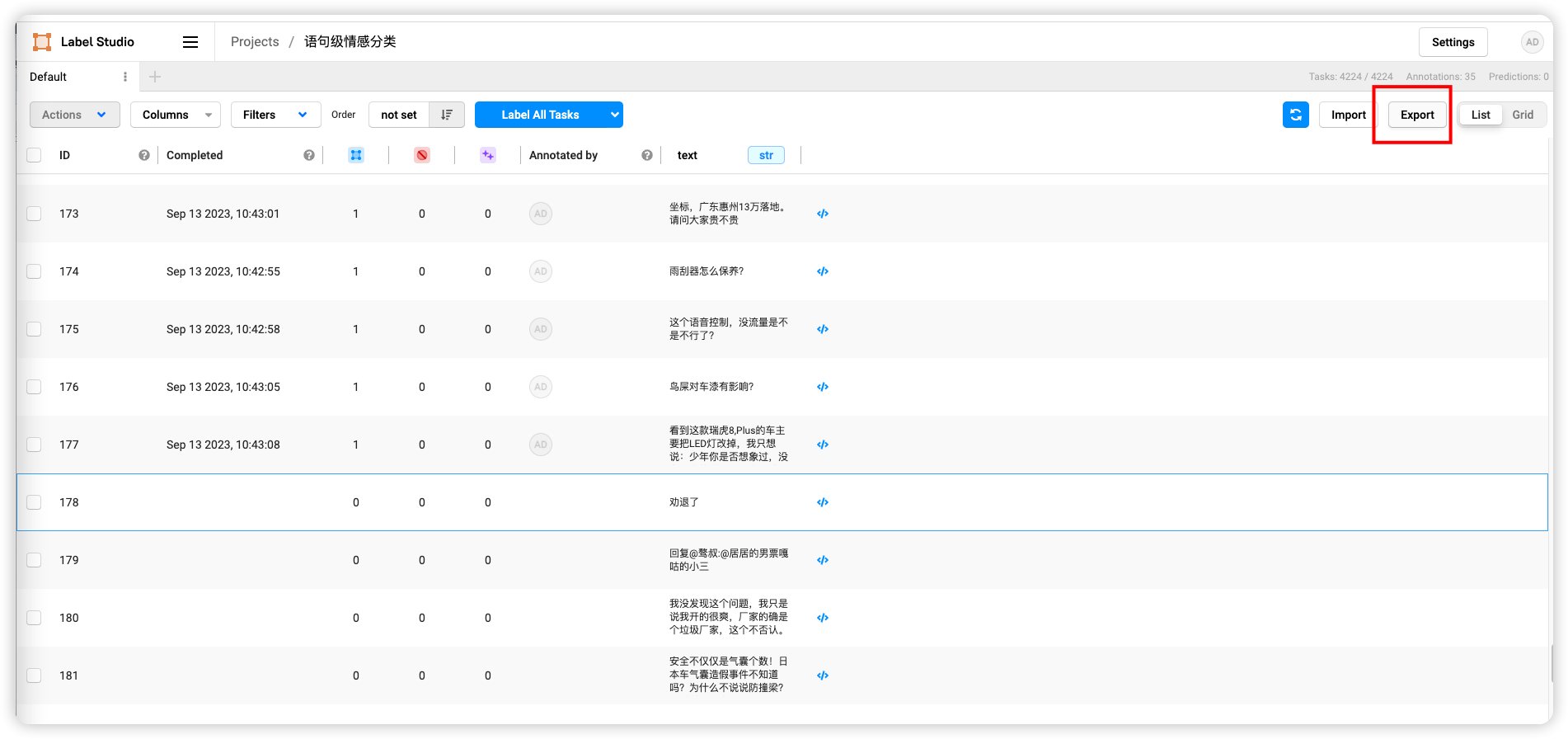
导出JSON格式
上传到服务器,目录statement/data1
ls statement/data1/
project-8-at-2023-09-13-02-43-0e9fdb25.json
2
执行构造数据集命令
python label_studio.py \
--label_studio_file ./statement/data1/project-8-at-2023-09-13-02-43-0e9fdb25.json \
--task_type cls \
--save_dir ./statement/data1 \
--splits 0.8 0.1 0.1 \
--options "正向" "负向" "中性" \
--is_shuffle True \
--seed 1000
2
3
4
5
6
7
8
执行结果
[2023-09-13 10:52:02,605] [ INFO] - Save 32 examples to ./statement/data1/train.json.
[2023-09-13 10:52:02,606] [ INFO] - Save 4 examples to ./statement/data1/dev.json.
[2023-09-13 10:52:02,606] [ INFO] - Save 5 examples to ./statement/data1/test.json.
[2023-09-13 10:52:02,606] [ INFO] - Finished! It takes 0.00 seconds
2
3
4
查看文件
$ ll statement/data1/
total 60
drwxr-xr-x 2 aistudio aistudio 4096 Sep 13 10:52 ./
drwxr-xr-x 3 aistudio aistudio 4096 Sep 13 10:46 ../
-rw-r--r-- 1 aistudio aistudio 612 Sep 13 10:52 dev.json
-rw-r--r-- 1 aistudio aistudio 35499 Sep 13 10:46 project-8-at-2023-09-13-02-43-0e9fdb25.json
-rw-r--r-- 1 aistudio aistudio 881 Sep 13 10:52 test.json
-rw-r--r-- 1 aistudio aistudio 5293 Sep 13 10:52 train.json
2
3
4
5
6
7
8
模型训练
python -u -m paddle.distributed.launch --gpus "0" finetune.py \
--train_path ./statement/data1/train.json \
--dev_path ./statement/data1/dev.json \
--save_dir ./statement/checkpoint \
--learning_rate 1e-5 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 100 \
--model uie-senta-base \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device gpu
2
3
4
5
6
7
8
9
10
11
12
13
模型测试
python evaluate.py \
--model_path ./statement/checkpoint/model_best \
--test_path ./statement/data1/test.json \
--batch_size 16 \
--max_seq_len 512
2
3
4
5
测试结果
[2023-09-13 11:05:24,719] [ INFO] - -----------------------------
[2023-09-13 11:05:24,719] [ INFO] - Class Name: all_classes
[2023-09-13 11:05:24,719] [ INFO] - Evaluation Precision: 0.60000 | Recall: 0.60000 | F1: 0.60000
2
3
可能不是很准,因为我标注的数量比较少
调用模型
from paddlenlp import Taskflow
schema = ['情感倾向[正向,负向,中性]']
senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema, task_path="./statement/checkpoint/model_best")
senta("一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知人们。")
2
3
4
测试结果
>>> senta("一款11kw 一款6.7kw,并且购买月份一致同为4月下单,是否存在差异,未告知人们。")
[{'情感倾向[正向,负向,中性]': [{'text': '中性', 'probability': 0.9685614691064188}]}]
>>> senta("哈弗H6全包多钱")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.4435399216482949}]}]
>>>
>>> senta("座椅很漂亮,就是不知道坐起来舒不舒服,性价比还是高,动力上也很强")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.9992767077484643}]}]
>>>
>>> senta("隔热去哪里了")
[{'情感倾向[正向,负向,中性]': [{'text': '负向', 'probability': 0.8288550459336292}]}]
>>>
>>> senta("支持国产品牌")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.9996183814416781}]}]
>>>
>>> senta("要颜值有颜值,有配置有配置,期待长安汽车继续多出些好车")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.5488139166910777}]}]
>>>
>>> senta("艾瑞泽8gt展车已到店")
[{'情感倾向[正向,负向,中性]': [{'text': '中性', 'probability': 0.9996157635229821}]}]
>>> senta("色彩缤纷,美轮美奂!")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.9957366342547544}]}]
>>>
>>> senta("比亚迪骂骂咧咧的退出群聊[看]")
[{'情感倾向[正向,负向,中性]': [{'text': '中性', 'probability': 0.7005535193248846}]}]
>>>
>>> senta("关掉电子档后挂档有后溜现象,如停车处有小斜坡不知怎样处理了?")
[{'情感倾向[正向,负向,中性]': [{'text': '负向', 'probability': 0.9609905327057362}]}]
>>>
>>> senta("你在乱说,什么1.5T的是6AT的?那是双离合的好不好!")
[{'情感倾向[正向,负向,中性]': [{'text': '负向', 'probability': 0.9801606187824916}]}]
>>>
>>> senta("发机下面有底板莫 我7月9号去看了 发动机下面没底板 档泥板")
[{'情感倾向[正向,负向,中性]': [{'text': '负向', 'probability': 0.8622748728464913}]}]
>>>
>>> senta("车上的软线管需要保养?")
[{'情感倾向[正向,负向,中性]': [{'text': '中性', 'probability': 0.9998082014327565}]}]
>>> senta("安全不仅仅是气囊个数!日本车气囊造假事件不知道吗?为什么不说说防撞梁?不说说硼钢占比?")
[{'情感倾向[正向,负向,中性]': [{'text': '负向', 'probability': 0.9743531421478657}]}]
>>> senta("日系车内部显空间大,有一部分原因就是马鞍宽度窄一点,你像楼主说的第二个问题就是这个原因。现在国产车为了体现豪华感,把马鞍做得很大,其实没必要,正常尺寸,然后座 椅更宽敞点更好。")
[{'情感倾向[正向,负向,中性]': [{'text': '正向', 'probability': 0.9937770266285426}]}]
>>>
>>> senta("这个建议很中肯,值得呼吁厂家改进(本人试驾两次都纠结上述问题)!")
[{'情感倾向[正向,负向,中性]': [{'text': '中性', 'probability': 0.8667076396928941}]}]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
最终调用有些准,有些不准,增大训练样本数据就好了。