 ElasticSearch Script操作数据
ElasticSearch Script操作数据
[toc]
# ElasticSearch Script基础介绍
语法
"script": {
"lang": "...",
"source" | "id": "...",
"params": { ... }
}
2
3
4
5
参数说明:
| 字段 | 说明 |
|---|---|
| lang | 脚本使用的语言,默认是painless |
| source | 脚本的核心部分,id应用于:stored script |
| params | 传递给脚本使用的变量参数 |
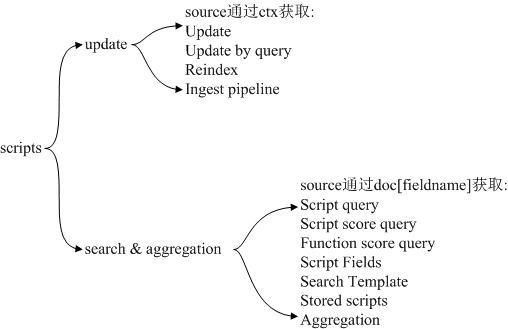
Script有许多场景使用,比如update、update-by-query、reindex等,结合scripts语法说,lang会有painless、expression、mustache等选择;source中有ctx、doc['field_name']、_source等方式取值。
# 基础用法
# List类型数据新增、删除
添加数据到List
PUT test/_doc/1
{
"counter" : 1,
"tags" : ["red"]
}
2
3
4
5
使用Script添加数据到List
POST test/_update/1
{
"script" : {
"source": "ctx._source.tags.add(params.tag)",
"lang": "painless",
"params" : {
"tag" : "blue"
}
}
}
2
3
4
5
6
7
8
9
10
使用Script删除List数据
POST test/_update/1
{
"script": {
"source": "if (ctx._source.tags.contains(params.tag)) { ctx._source.tags.remove(ctx._source.tags.indexOf(params.tag)) }",
"lang": "painless",
"params": {
"tag": "blue"
}
}
}
2
3
4
5
6
7
8
9
10
11
# nested数据新增、删除
新增nested类型数据
POST group/_update/50Bh5H8BmwYplCYFGcvg
{
"script" : {
"source": "ctx._source.user.add(params.user)",
"lang": "painless",
"params": {
"user": {
"userId":"3005",
"userName":"小卡",
"content":"不返回具体数据。"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
删除nested类型数据
POST group/_update_by_query
{
"script" : {
"source": "ctx._source.user.removeIf(item -> item.userId == params.userId)",
"lang": "painless",
"params": {
"userId": "3003"
}
},
"query": {
"term": {
"user.content.keyword": {
"value": "不返回具体数据。"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 根据指定条件修改数据
SQL含义:
update operator_ip_segment_index set owned_network = '广电网' where owned_network.keyword = '新疆伊犁哈萨克自治州';
DSL语法:
curl -XPOST http://8.9.60.9:9200/operator_ip_segment_index/_update_by_query -H 'Content-Type: application/json' -d'
{
"script":{
"source":"ctx._source.owned_network = params.owned_network",
"params":{
"owned_network":"广电网"
},
"lang":"painless"
},
"query":{
"term":{
"owned_network.keyword":"新疆伊犁哈萨克自治州"
}
}
}
'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 根据指定条件修改多个字段数据-查询条件也使用脚本
POST operator_ip_segment_index/_update_by_query
{
"script":{
"source":"""
ctx._source['ip_type_code']=null;
ctx._source['start_ipv4_num']=null;
"""
},
"query": {
"bool": {
"should": {
"script": {
"script": {
"source": """
long times = System.currentTimeMillis()/1000 - 60 * 60 * 24;
doc['update_time_seconds'].value <= times
"""
, "lang": "painless"
}
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 根据指定条件删除nested中子数据
# 数据
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.8025915,
"hits" : [
{
"_index" : "group",
"_type" : "_doc",
"_id" : "ri8VboYBHSuebtDIpIft",
"_score" : 0.8025915,
"_source" : {
"groupName" : "聊天2群",
"groupId" : "1002",
"user" : [
{
"userName" : "小王2",
"userId" : "3002",
"content" : "2作为一级筛选条件单独使用表示,表示只返回聚合结果,不返回具体数据。"
},
{
"userName" : "小张2",
"userId" : "3003",
"content" : "2作为一级筛选条件单独使用表示,表示只返回聚合结果,不返回具体数据。"
},
{
"userName" : "小卡",
"userId" : "说啥呢",
"content" : "不返回具体数据。"
}
]
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
# 根据条件删除数据
查询user.content.keyword = 不返回具体数据。的数据,并删除,nested中userId=3003的子数据
POST group/_update_by_query
{
"script" : {
"source": "ctx._source.user.removeIf(item -> item.userId == params.userId)",
"lang": "painless",
"params": {
"userId": "3003"
}
},
"query": {
"term": {
"user.content.keyword": {
"value": "不返回具体数据。"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 删除之后结果
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.8025915,
"hits" : [
{
"_index" : "group",
"_type" : "_doc",
"_id" : "ri8VboYBHSuebtDIpIft",
"_score" : 0.8025915,
"_source" : {
"groupName" : "聊天2群",
"groupId" : "1002",
"user" : [
{
"userName" : "小王2",
"userId" : "3002",
"content" : "2作为一级筛选条件单独使用表示,表示只返回聚合结果,不返回具体数据。"
},
{
"userName" : "小卡",
"userId" : "说啥呢",
"content" : "不返回具体数据。"
}
]
}
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 创建脚本,通过脚本调用
# 根据条件查询出数据,删除nested子对象数据
创建删除脚本,id为delete-nested-test
POST _scripts/delete-nested-test
{
"script":{
"lang":"painless",
"source":"ctx._source.user.removeIf(item -> item.userId == params.userId)"
}
}
2
3
4
5
6
7
使用delete-nested-test脚本,删除nested,user.userId等于888的子对象数据
POST group/_update_by_query
{
"script": {
"id":"delete-nested-test",
"params":{
"userId":"888"
}
},
"query": {
"term": {
"user.content.keyword": {
"value": "不返回具体数据。"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 根据条件修改数据-异步执行,并根据任务id查询进度
curl -u elastic:Asdfghjk8888888@ -H 'Content-Type:application/json' -XPOST "http://10.86.50.206:9200/ads_user_profile/_update_by_query?wait_for_completion=false&conflicts=proceed" -d '
{
"script":{
"source":"ctx._source[\u0027is_delete\u0027]=null;"
},
"query": {
"term": {
"is_delete": {
"value": "3"
}
}
}
}
'
2
3
4
5
6
7
8
9
10
11
12
13
14
参数说明:
- conflicts=proceed
在 Elasticsearch 中,conflicts=proceed 是一种写操作的参数配置,用于处理文档版本冲突的情况。当多个客户端同时对同一文档进行写操作时,可能会发生版本冲突的情况。此时,Elasticsearch 会返回一个版本冲突的错误,提示客户端需要在冲突的情况下重新尝试更新该文档。而如果设置 conflicts=proceed 参数,Elasticsearch 会在发生冲突时自动扩展新版本号,而不是返回错误。
使用 conflicts=proceed 参数可以帮助客户端减少处理冲突的时间和工作量。但是,需要注意的是,当设置该参数时,如果出现冲突的文档在后续更新时需要依赖先前的版本,在冲突处理时可能会导致数据不一致。如果对数据一致性有较高的要求,则建议使用默认的冲突处理方式,即返回版本冲突错误,由客户端处理后再次提交操作。
- wait_for_completion=false
在 Elasticsearch 中,wait_for_completion=false 是一种参数设置,用于异步执行一些操作时防止线程被阻塞,从而提高性能。具体来说,该参数主要用于异步执行一些 long-running 的任务,例如 restore 操作、reindex 操作等,如果不使用该参数,则这些操作会在执行期间一直阻塞客户端的线程,从而会影响其他操作的响应时间。而通过设置 wait_for_completion=false,Elasticsearch 会在后台异步执行这些操作,从而避免了这种线程阻塞的情况,提高了性能。
需要注意的是,当设置 wait_for_completion=false 时,Elasticsearch 会在任务开始执行后立即返回一个任务 ID,然后客户端可以根据该 ID 在后续的操作中查询任务的状态和结果。因此,如果需要获取任务执行过程中的详细信息和结果数据,则需要使用异步方式。
总的来说,wait_for_completion=false 参数在一些需要异步执行的任务中非常有用,可以避免线程阻塞和性能影响问题,但需要注意合理使用,以免影响数据一致性或增加操作的复杂度。
返回
{"task":"ggZOAkegTH29aUCAj_eKVg:1963952216"}
查看任务状态
取消任务
POST /_tasks/{task_id}/_cancel
curl -u elastic:Asdfghjk8888888@ -H 'Content-Type:application/json' -XGET "http://10.86.50.206:9200/_tasks/ggZOAkegTH29aUCAj_eKVg:1963952216"
{
"completed":false,
"task":{
"node":"ggZOAkegTH29aUCAj_eKVg",
"id":1963952216,
"type":"transport",
"action":"indices:data/write/update/byquery",
"status":{
"total":49037601,
"updated":164730,
"created":0,
"deleted":0,
"batches":166,
"version_conflicts":270,
"noops":0,
"retries":{
"bulk":0,
"search":0
},
"throttled_millis":0,
"requests_per_second":-1,
"throttled_until_millis":0
},
"description":"update-by-query [ads_user_profile_audi] updated with Script{type=inline, lang='painless', idOrCode='ctx._source['is_delete']=null;', options={}, params={}}",
"start_time_in_millis":1683732140856,
"running_time_in_nanos":32754573141,
"cancellable":true,
"cancelled":false,
"headers":{
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
{
"completed":false,
"task":{
"node":"ggZOAkegTH29aUCAj_eKVg",
"id":1963952216,
"type":"transport",
"action":"indices:data/write/update/byquery",
"status":{
"total":49037601,
"updated":433481,
"created":0,
"deleted":0,
"batches":436,
"version_conflicts":1519,
"noops":0,
"retries":{
"bulk":0,
"search":0
},
"throttled_millis":0,
"requests_per_second":-1,
"throttled_until_millis":0
},
"description":"update-by-query [ads_user_profile_audi] updated with Script{type=inline, lang='painless', idOrCode='ctx._source['is_delete']=null;', options={}, params={}}",
"start_time_in_millis":1683732140856,
"running_time_in_nanos":133641317970,
"cancellable":true,
"cancelled":false,
"headers":{
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 根据条件查询,直接删除某个字段
POST index/_update_by_query
{
"script":{
"source":"ctx._source.remove('owner_pinyin')"
},
"query": {
"term": {
"zip_code": {
"value": "133700"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13